

Come utilizzare il linguaggio di markup con JSON-LD basato su Schema.org

I dati strutturati aiutano i motori di ricerca a comprendere meglio le pagine web. Un’annotazione semantica consente di creare dei collegamenti, di scansionare automaticamente le informazioni e di trasporle in altre forme di rappresentazione. Google, il motore di ricerca più utilizzato dei giorni nostri, si basa sui dati strutturati per mettere a disposizione degli utenti i Rich Search Results e gli altri elementi della SERP. Il vantaggio per i gestori dei siti è che i risultati di ricerca messi in evidenza in questo modo balzano subito agli occhi e aumentano la visibilità di un’offerta web.
Il prerequisito è che tutte le informazioni rilevanti vengano contrassegnate adeguatamente con il linguaggio di markup. Con il tempo la community Internet ha sviluppato diversi standard per la strutturazione dei dati. Quindi vi indichiamo perché dovreste preferire JSON-LD agli altri formati di dati alternativi, come i microformati, RDFa o i microdati.
- Certificato SSL Wildcard incluso
- Registrazione di dominio sicura
- Indirizzo e-mail professionale da 2 GB
Che cos’è JSON-LD?
JSON-LD è un metodo basato sul formato JSON che serve per l’integrazione dei dati strutturati in un sito web. Contrariamente agli altri formati per la strutturazione dei dati come i microformati, RDFa e i microdati, la segnalazione non avviene come un’annotazione del codice sorgente, ma i metadati vengono implementati sotto forma di un tag script separati dal contenuto del sito nell’elemento head o implementati all’interno del body del documento HTML. Così JSON-LD si serve dell’annotazione JSON e la amplia di una sintassi con cui i dati si possono segnalare secondo uno schema universale e uniforme a livello globale.
La specificazione JSON-LD è stata creata dal fondatore di Digital Bazaar, Manu Sporny, e dal 16 gennaio 2014 è consigliata ufficialmente dal W3C.
JSON-LD è una sintassi consigliata dal W3C, con la quale si possono integrare i dati strutturati, oltre che lo schema universale per la strutturazione dei dati nel formato compatto JSON.
JSON
L’acronimo JSON sta per JavaScript Object Notation e indica un formato compatto basato sul testo per lo scambio di dati, facile da elaborare sia per gli esseri umani che per le macchine. Il formato JSON deriva da JavaScript, ma si può utilizzare indipendentemente dal linguaggio di programmazione su qualsiasi piattaforma. Come formato dati per la serializzazione, cioè la riproduzione di oggetti programmabili sotto forma di rappresentazione sequenziale, JSON viene usato per la trasposizione e la memorizzazione dei dati strutturati nelle applicazioni web e nelle app Mobile.
La sintassi di un oggetto JSON è essenzialmente costituita da coppie di nomi e valori (name-value pairs), che (ad eccezione dei valori numerici) sono racchiuse tra virgolette e vengono annotate separatamente da un doppio punto. Ogni coppia nome-valore comincia solitamente in una nuova riga e finisce con una virgola. L’unica eccezione è rappresentata dall’ultima coppia nome-valore prima della parantesi graffa conclusiva, che viene annotata senza virgola.
Il seguente esempio chiarisce lo schema di base della sintassi JSON:
{
"name": "Manu Sporny",
"homepage": "http://manu.sporny.org/about/"
}In questa parte di testo si trova la coppia di parole “Manu Sporny”: un lettore in carne e ossa comprenderà subito per via del contesto che con questa sequenza di lettere viene indicato un nome e che viene inserito un link al sito dello sviluppatore di JSON-LD. Invece i programmi come browser e crawler hanno bisogno dei metadati per fare questa associazione, possibile proprio ricorrendo a JSON.
Il codice di esempio indica entrambi gli elementi del nome “name“ e “homepage” con i loro rispettivi valori. Un programma, che scansiona una pagina web con questo oggetto JSON, è quindi in grado di identificare “Manu Sporny” come nome e “http://manu.sporny.org/about/” come homepage.
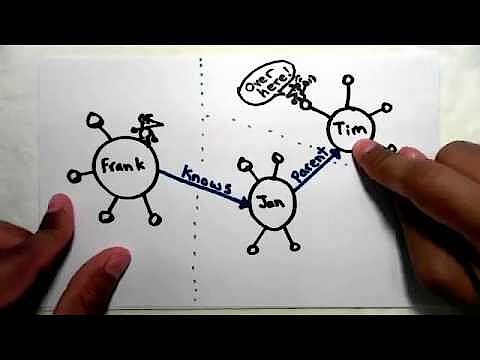
Linked Data (LD)
Il markup con JSON funziona senza problemi all’interno di un sito, ma l’analisi dei dati con questo formato su diversi siti può portare a delle ambiguità. Di solito i programmi analizzano molte pagine e valutano le informazioni raccolte nei database. Considerando il codice sopra, non si può garantire che gli elementi “name” e “homepage” mantengano sempre lo stesso valore su siti diversi. Quindi, per evitare ambiguità, il formato JSON-LD aggiunge alla classica annotazione JSON degli elementi di supporto al contesto, sulla base di Linked Data. Per essere più precisi si tratta di dati disponibili liberamente su Internet, che possono essere richiamati tramite Uniform Resource Identifier (URI).
Il seguente video di Manu Sporny, lo sviluppatore di JSON-LD, fornisce ulteriori informazioni sui Linked Data:
 Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui. Per preparare JSON per i Linked Data, JSON-LD aggiunge le classiche coppie nome-valore dell’annotazione JSON tramite keyword (parole chiave), introdotte dal simbolo @ anteposto. Sono molto importanti le keyword @context e @type. Mentre @context definisce il markup del vocabolario alla base, @type indica di quale tipo di dati (schema) si tratti.
Un database standardizzato per la strutturazione dei dati è fornito dal progetto schema.org. Sull’omonimo sito del progetto i gestori dei siti trovano diversi schemi di dati (types), oltre che queste “properties“ (caratteristiche) assegnate a questo tipo di dati, che consentono un markup semantico dettagliato dei contenuti web.
Aggiunto con i rispettivi elementi di contesto, per l’esempio introdotto sopra risulta il seguente codice:
{
"@context": "http://schema.org/",
"@type": "Person",
"name": "Manu Sporny",
"url": "http://manu.sporny.org/about/"
}La keyword @context nella riga 2 definisce il vocabolario alla base del markup semantico, che è in questo caso schema.org. Nella riga 3 viene introdotto il tipo di dati “Person” ricorrendo alla keyword @type. Questo tipo di dati viene meglio specificato nelle righe 4 e 5 tramite le proprietà “name“ e “url“. Un programma, che analizza questo codice di esempio, può identificare così l’elemento testuale contrassegnato come “name”, cioè “Manu Sporny”, ovvero il nome di una persona in base al tipo di dati “Person” ricorrendo a Schema.org. Le coppie di nomi e valori introdotte con “name” e “URL” vengono elaborate come proprietà (properties) dello schema “Person”. A stabilire quali proprietà si possano assegnare a uno schema è il vocabolario di base.
 Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui. I vantaggi di JSON-LD rispetto agli altri formati di dati
Su JSON-LD l’assegnazione di schemi e proprietà per il markup semantico dei contenuti web avviene in maniera analoga agli altri formati. Se convertito in un’annotazione del codice sorgente, lo script di esempio introdotto sopra si può mettere in evidenza anche tramite microdati e RDFa basati su Schema.org, senza rischiare di incorrere in una perdita di informazioni.
Sintassi dei microdati in base a Schema.org:
<div itemscope itemtype="http://schema.org/Person">
<span itemprop="name">Manu Sporny</span>
<span itemprop="url">http://manu.sporny.org/about/</span>
</div>Sintassi RDFa in base a schema.org:
<div vocab="http://schema.org/" typeof="Person">
<span property="name">Manu Sporny</span>
<span property="url">http://manu.sporny.org/about/</span>
</div>Rispetto agli altri formati concorrenti, JSON-LD ha il vantaggio che i metadati non devono essere direttamente integrati nel codice HTML, ma possono essere implementati separatamente in un qualsiasi punto. Ciò è possibile grazie al tag <script> ricorrendo allo schema seguente:
<script type="application/ld+json">
{
JSON-LD
}
</script>Riferendosi all’esempio introdotto sopra ne emerge il seguente markup basato su schema.org:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Person",
"name": "Manu Sporny",
"url": "http://manu.sporny.org/about/"
}
</script>Anche se JSON viene annotato con tag script, non si tratta di un codice eseguibile.
La distinzione netta tra HTML e annotazione semantica non punta solo a una migliore leggibilità del codice sorgente, infatti un’implementazione di questo tipo consente una generazione dinamica dei dati strutturati, indipendentemente dai contenuti visibili agli utenti. Con il formato JSON-LD i metadati possono essere gestiti dal back end, scansionati da un database e venir generati automaticamente tramite template. Così è possibile una pratica annotazione semantica, anche per i contenuti dinamici che acquistano sempre più importanza in rete.
Grazie a un credito iniziale, puoi provare gratuitamente il Server Cloud di IONOS per 1 mese (o fino all’esaurimento del credito) e beneficiare del giusto mix di prestazioni e sicurezza!
JSON-LD e l’ottimizzazione per i motori di ricerca
Da giugno 2013 il progetto schema.org ha indicato JSON-LD come uno dei formati preferiti in assoluto e anche Google consiglia (se possibile) l'integrazione dei metadati basati su script tramite JSON-LD. Un markup di questo tipo rappresenta la base per diversi elementi della SERP che il motore di ricerca utilizza per presentare agli utenti dei risultati di ricerca ampliati.
Google utilizza diverse forme di rappresentazione per i risultati di ricerca: oltre ai Basic Results (i risultati di ricerca classici), da alcuni anni agli utenti vengono anche mostrati, a seconda della richiesta effettuata, Featured Results e Knowledge Graph Results. Mentre i Basic Results a volte presentano solo dei semplici ampliamenti, come breadcrumbs, i Featured Results e i Knowledge Graph Results offrono potenzialmente delle estensioni complete, chiamate da Google anche Enhancements o Search Result Features.
Nella terminologia di Google il termine Featured Result viene utilizzato per i risultati di ricerca ampliati, dove i contenuti presentati provengono solo da una fonte, cioè il sito linkato. Altre denominazioni per gli elementi SERP di questo tipo sono Rich Search Result e Rich Cards. Se un Featured Result consente interazioni tra utenti, Google parla di un Enriched Search Result. Invece, nei Knowledge Graph Results il motore di ricerca non si appoggia a un singolo sito, bensì all'algoritmo di Knowledge Graph che raccoglie i contenuti provenienti da diverse fonti in rete. I Knowledge Graph Results vengono anche chiamati Knowledge Graph Cards, Knowledge Graph Boxes o Knowledge Graph Displays. Se per una richiesta Google trova più Rich cards o Knowledge Graph Cards rilevanti, allora queste vengono presentate nelle SERPs nel carosello, un formato a lista per diversi tipi di dati.
Al momento Google supporta il markup JSON-LD per le seguenti estensioni. Il motore di ricerca mette a disposizione per ogni Search Result Feature un esempio nella Search Gallery all'indirizzo developers.google.com.
- Breadcrumbs: questo tipo di navigazione, chiamata breadcrumbs, indica la posizione della pagina web corrente nella gerarchia del sito. I gestori dei siti che segnalano semanticamente i breadcrumbs consentono a Google di mostrarli nelle SERPs. I breadcrumbs rientrano tra le poche Search Results Features che Google fa comparire anche nei Basic Results.
- Informazioni di contatto dell'azienda: se le informazioni di contatto dell'azienda sono state contrassegnate semanticamente, Google può mostrarle nelle SERPs come Knowledge Graph Display, una forma di rappresentazione dell'algoritmo di Knowledge Graph.
- Loghi: con un markup del logo i gestori dei siti chiariscono quale grafica deve utilizzare il motore di ricerca come logo dell'azienda, così Google amplia i risultati di ricerca della relativa azienda con il logo appropriato.
- Sitelinks Searchbox: Se un sito mette a disposizione una funzione di ricerca ed è stata segnalata semanticamente, Google mostra i risultati del sito anche con una Sitelinks Searchbox.
- Link ai profili social: se viene utilizzato un markup per i link ai profili dei social media, Google amplia il Knowledge Graph Display alle persone o alle organizzazioni con i relativi pulsanti. Al momento Google supporta un markup con JSON-LD per Facebook, Twitter, Google+, Instagram, YouTube, LinkedIn, Myspace, Pinterest, SoundCloud e Tumblr.
I gestori di siti che vogliono posizionare i loro contenuti in maniera ben visibile nelle SERPs di Google hanno la possibilità di segnalare semanticamente i diversi tipi di dati. In questo caso bisogna fare attenzione al fatto che Google è il solo che stabilisce se un risultato venga mostrato come Basic Result o con delle estensioni. Per ora Google supporta il markup JSON-LD per i seguenti tipi di dati e li utilizza per presentare le informazioni sotto forma di Rich Search Results, Enriched Search Results o Knowledge Graph Results.
- Articolo: i gestori di siti che contrassegnano semanticamente gli articoli dei blog o di news consentono a Google di inserirli nel carosello tra le top stories o di aggiungerle nelle SERPs con Search Result Features, come titoli o immagini di anteprima.
- Libri: se i gestori dei siti offrono un markup JSON-LD per le informazioni che si riferiscono ai libri, Google crea una Knowledge Graph Card per le richieste rilevanti che non contiene solo informazioni esaustive sul libro, ma consente agli utenti anche l'acquisto direttamente sul motore di ricerca, se richiesto.
- Musica (informazioni su musicisti e album): in modo analogo alle informazioni sui libri si possono annotare anche le offerte di musica. Ciò consente a Google di generare le Knowledge Graph Cards per contenuti musicali, così gli utenti non ricevono solo informazioni su album e musicisti, bensì hanno anche la possibilità di interagire con il contenuto, infatti possono ascoltare o acquistare la musica.
- Corsi: ai gestori dei siti che segnalano i corsi (ad esempio corsi di lingua) con un markup JSON-LD che consente di rilevare automaticamente il titolo, una breve descrizione e l'organizzatore, Google dà la possibilità di mostrare queste informazioni come risultati di ricerca ampliati nelle SERPs.
- Eventi: gli organizzatori degli eventi pubblici, come concerti e festival, hanno la possibilità di annotare informazioni rilevanti (ad esempio il luogo, la data e l'ora dell'evento) tramite JSON-LD, di modo che Google estragga automaticamente queste informazioni e le elenchi nelle SERPs o le possa indicare in altri servizi di Google, come Maps.
- Annunci di lavoro: anche le offerte di lavoro che gli organizzatori pubblicano sul loro sito si possono contrassegnare, così che Google possa scansionare le informazioni rilevanti per i risultati di ricerca ampliati.
- Immissione di fornitori locali: i fornitori locali che utilizzano i dati strutturati per il sito del loro negozio o il loro ristorante consentono a Google di creare Knowledge Graph Cards, che vengono mostrate nei risultati di ricerca rilevanti nelle SERPs o su Google Maps. Se ad esempio un utente cerca un ristorante vietnamita, Google attiva un carosello con i fornitori appropriati che si trovano nei paraggi.
- Set di dati: anche set di dati come tabelle CSV o file in formati proprietari si possono rendere accessibili per il motore di ricerca tramite il markup con JSON-LD.
- Podcast: Google supporta un markup con JSON-LD per le informazioni podcast. Le offerte contrassegnate in modo appropriato possono essere indicate e attivate direttamente nel motore di ricerca.
- Video: i fornitori di contenuti che mettono a disposizione i dati strutturati per i video sul loro sito, come una descrizione, un link a un'immagine di anteprima, la data di upload o la durata, consentono a Google di estrarre queste informazioni e di attivarle come Rich Cards o sotto forma di carosello nelle SERPs.
- Film e show: se un sito presenta dei dati strutturati per film e show, Google li riproduce nelle richieste corrispondenti come Knowledge Graph Card sulle SERPs. Se necessario, si possono ampliare con elementi interattivi che consentono di usufruire dell’offerta o di acquistarla.
- Ricette: da alcuni anni Google offre anche le ricette di cucina come Featured Result nel motore di ricerca. Il requisito è che chi mette a disposizione i contenuti inserisca tutte le informazioni rilevanti sulla ricetta sotto forma di dati strutturati. Una possibile rappresentazione nelle SERPs è un carosello con le appropriate Rich Cards in risposta alla richiesta effettuata.
- Valutazioni: Google supporta le valutazioni per diversi tipi di dati basati su schema.org, come negozi locali, ristoranti, prodotti, libri, film o lavori creativi. La rappresentazione dei relativi contenuti avviene tramite snippet. Qui Google distingue tra critiche dei singoli autori e post sui portali di recensione. Se è presente un'annotazione semantica, entrambi i tipi di valutazione vengono visualizzati nelle richieste corrispondenti come Featured Results nelle SERPs.
- Prodotti: i commercianti online che mettono a disposizione sul loro sito informazioni dei prodotti come prezzi, disponibilità o valutazioni come dati strutturati, consentono a Google di far comparire queste informazioni nelle relative richieste come Rich Search Results.
I risultati di ricerca avanzati, indipendentemente dal fatto che si tratti di Featured Results o Knowledge Graph Displays, sono vantaggiosi per i gestori dei siti soprattutto per un motivo: risaltano nei risultati di ricerca nelle SERPs rispetto a quelli di altri siti.
Google presenta i risultati display e a carosello per i Featured Results nel punto predisposto sopra i Basic Results e quindi nella posizione zero. I Knowledge Graph Displays compaiono sia come carosello sul lato superiore della pagina che sulla destra delimitati da una cornice, accanto alla ricerca organica. I risultati di ricerca ampliati offrono ai gestori dei siti la possibilità di conquistare così le prime posizioni delle SERPs, senza che debba essere investito tempo e denaro per migliorare il ranking organico.
Ma non è solo una posizione di primo piano a risvegliare l'attenzione degli utenti e a invogliarli a cliccare, contribuiscono a tal proposito anche i diversi ampliamenti come immagini di anteprima, valutazioni, parti di testo ed elementi interattivi. I gestori dei siti possono partire dal presupposto che la Click Through Rate aumenti notevolmente nei risultati ampliati rispetto a quella dei Basic Results.
Inoltre ai risultati di ricerca ampliati viene attribuito un effetto positivo sulla frequenza di rimbalzo. A differenza dei Basic Results, che comprendono solitamente solo i meta title, un URL e una breve descrizione, i risultati di ricerca ampliati danno agli utenti un'impressione completa di quali contenuti si debbano aspettare dal link al sito collegato. Quindi un utente può verificare la rilevanza di un sito in relazione alla propria ricerca ancora prima di aprire la pagina e cliccarvi sopra solo se attinente alle sue aspettative.
Google non privilegia però come fattore di ranking la presenza o la mancanza di un markup semantico tramite JSON-LD, come già nel 2012 chiariva Matt Cutts, l'ex capo del team del web spam di Google, nel seguente video YouTube della serie di Google Webmasters:
 Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui. Come per il suo utilizzo, anche nell'indicizzazione JSON-LD punta alla memorizzazione del markup in parti di script separati. Rispetto alle annotazioni alternative, come i microdati o RDFa, JSON-LD consente, malgrado l'annotazione semantica, un codice sorgente leggero, che può essere analizzato e indicizzato facilmente dal Google bot e dagli altri crawler.
Tuttavia la memorizzazione separata dei dati strutturati presenta anche degli svantaggi. Essenzialmente su Google e gli altri motori di ricerca vale la regola che devono essere contrassegnati i contenuti che devono leggere le macchine e che sono a disposizione dei visitatori in carne e ossa delle pagine. Però teoricamente con JSON-LD si può implementare un qualsiasi markup, anche quando per i metadati indicati non c'è nessuna corrispondenza nel contenuto del sito vero e proprio. In questo caso sia al motore di ricerca sia all'utente viene attribuito un possibile valore aggiunto che un sito abbellito in una maniera simile non offre. In altri termini sarebbe meglio tenersi alla larga da un procedimento del genere, altrimenti i gestori del sito corrono il rischio di essere penalizzati per via di azioni spam.
Per evitare che i webmaster superino inavvertitamente i limiti dell'annotazione semantica conforme ai motori di ricerca, Google offre delle linee guida generali per i dati strutturati, ovvero un regolamento esaustivo che si può riassumere essenzialmente nei seguenti punti:
- Formato: i dati strutturati devono essere in uno dei tre formati affermati, cioè microdati, RDFa o JSON-LD. Google consiglia quest’ultimo.
- Accessibilità: le pagine con i dati strutturati devono essere accessibili per il Google bot. I metodi di Access Control (ad esempio tramite robot.txt o l'attributo noindex) impediscono la scansione dei metadati.
- Equivalenza del contenuto: il markup JSON-LD può descrivere solo entità che possono anche essere descritte nel codice HTML.
- Rilevanza: un markup JSON-LD dovrebbe riferirsi solo alle corrispondenze rilevanti dei tipi di dati utilizzati. Un gestore del sito che contrassegna delle istruzioni tecniche come una ricetta infrange, ad esempio, il criterio della rilevanza.
- Completezza: tutti i tipi di dati (types) presentati nel markup JSON-LD devono essere completi e comprensivi della segnalazione delle proprietà (properties) richieste. I tipi di dati in cui mancano delle proprietà essenziali non si adattano per i risultati di ricerca ampliati.
- Specificità: i progetti di Linked Data, come schema.org, offrono una molteplicità di tipi di dati. Per qualificare i propri contenuti per una rappresentazione dei risultati di ricerca ampliati, i gestori dovrebbero scegliere degli schemi i più specifici possibili.
Essenzialmente più vengono messe a disposizione proprietà sotto forma di dati strutturati, maggiore sarà il valore aggiunto per gli utenti di Google. Perciò Google prende in considerazione la quantità delle informazioni messe a disposizione per il ranking delle Rich Cards e anche i webmaster traggono beneficio da un markup il più possibile completo. Ad esempio, secondo Google gli utenti preferiscono annunci di lavoro con l’indicazione dello stipendio o valutazioni comprensive di una classificazione con stelle.
JSON-LD basato su schema.org: guida passo per passo
Di seguito vi mostriamo con un esempio come potete arricchire il vostro sito nella maniera più efficiente possibile con i metadati rilevanti. Alla base di questo tutorial JSON-LD si trova il vocabolario del progetto schema.org.
Primo passaggio: considerazioni preliminari
L’implementazione dei dati strutturati è collegata con un certo tipo di impegno a seconda della complessità del progetto web. Riflettete quindi preliminarmente su quali obiettivi volete raggiungere con il markup semantico e quante ore di lavoro volete investire nell’annotazione.
Solitamente un markup deve strutturare le informazioni del sito e offrirle in una forma leggibile per i motori di ricerca. L’obiettivo è quello di dimostrare a Google e agli altri motori di ricerca che un sito ottimizzato in questa maniera mette a disposizione le migliori risorse per le richieste rilevanti sul tema. Ponetevi perciò le seguenti domande:
- Quali sono i contenuti principali del vostro sito?
- Quale valore aggiunto offrono ai potenziali visitatori?
- Quali contenuti sono così rilevanti per il tema principale del vostro sito, tanto da dover essere segnalati nel modo migliore per i motori di ricerca?
Secondo passaggio: determinare i contenuti rilevanti
Create una lista di tutti i contenuti che offrono un valore aggiunto. Decidete su quali contenuti dovrebbe ricadere l’attenzione dei potenziali visitatori già dalle SERPs.
Ad esempio Google consiglia un markup con JSON-LD per le informazioni che riguardano gli eventi (events). Nell’HTML si possono presentare le informazioni dell’evento per concerti, musical o rappresentazioni teatrali, seguendo ad esempio questo schema:
<p>
<a href="http://www.example.org/magacirce/2017-11-20-2000">La grande maga Circe – una serata magica</a>,<br>
Ancora una volta torna la maga Circe per regalarvi una serata magica. Al suo fianco i suoi celebri assistenti: Polifemo e Ulisse. <br>
Data: 20.11.2017,<br>
Ingresso: 20:00,<br>
Spettacolo: dalle 20:30 alle 23:00,
<a href="http://www.example.org/events/magacirce/2017-11-20-2000/biglietti">Biglietti</a><br>
Prezzo: 100 Euro,<br>
Biglietti disponibili,<br>
<a href="http://www.example.com">Montagna Incantata</a>,<br>
Via della Montagna Incantata 1,<br>
27890 Città magica,<br>
</p>Informazioni tipiche del tipo di dati “Event“ sono la data e l’ora, il prezzo, la disponibilità dei biglietti, l’indirizzo del luogo degli eventi, così come i link alle informazioni aggiuntive sull’evento o sul luogo dello stesso. I visitatori reali sono in grado di desumere queste informazioni da una porzione di testo, da una tabella o da altre forme di rappresentazione e assegnarle alla corrispondente correlazione. I programmi come i crawler, invece, hanno bisogno di metadati che comprendono direttive su come vadano elaborate le informazioni offerte. JSON-LD li offre sotto forma di formati dati, che vengono aggiunti separatamente dal contenuto in un qualsiasi punto del codice sorgente HTML.
Schema.org mette a disposizione le regole generali su come realizzare un markup con JSON-LD e su come integrarlo nel vostro sito.
Terzo passaggio: selezionare uno schema
Schema.org offre ai gestori di siti un vocabolario completo per la strutturazione dei dati. Complessivamente il database comprende quasi 600 tipi, che si possono specificare meglio con più di 860 proprietà.
Per la scelta dei tipi di dati adeguati è possibile valutare due strategie:
- Teoricamente siete liberi di confrontare i contenuti stabiliti prima con i tipi di dati messi a disposizione dal vocabolario di schema.org e selezionare rispettivamente il tipo di dati specifico per il rispettivo elemento del content. Un simile procedimento è lungo e generalmente inutile.
- In pratica i gestori dei siti si limitano per la maggior parte a un sottoinsieme dei tipi di dati di schema.org: se ricorrendo al markup con JSON-LD perseguite solo lo scopo di mettere a disposizione del motore di ricerca i dati strutturati, basta prima di tutto limitarsi ai tipi di dati che sono attualmente supportati da Google e descritti esaurientemente nella sezione Google Developer.
Vi consigliamo la strategia “b” per il seguente motivo: Google mette a disposizione una documentazione esauriente per tutti i tipi di dati supportati dal motore di ricerca. Per ogni tipo di dati viene indicato un markup di esempio.
Utilizzate gli esempi che Google presenta nella sezione Developer come modello per il vostro markup JSON-LD.
Per inserire i dati strutturati nel vostro sito, non dovete fare nulla di così complicato. Anche se non avete alcuna esperienza con la sintassi di JSON-LD, risparmiate tempo ed energia ricorrendo agli schemi già pronti, al posto di riscrivere di nuovo da zero il markup per ogni tipo di dati.
Nella documentazione di Google i gestori dei siti trovano il seguente esempio di markup per gli eventi:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Event",
"name": "Jan Lieberman Concert Series: Journey in Jazz",
"startDate": "2017-04-24T19:30-08:00",
"location": {
"@type": "Place",
"name": "Santa Clara City Library, Central Park Library",
"address": {
"@type": "PostalAddress",
"streetAddress": "2635 Homestead Rd",
"addressLocality": "Santa Clara",
"postalCode": "95051",
"addressRegion": "CA",
"addressCountry": "US"
}
},
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/4x3/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
],
"description": "Join us for an afternoon of Jazz with Santa Clara resident and pianist Andy Lagunoff. Complimentary food and beverages will be served.",
"endDate": "2017-04-24T23:00-08:00",
"offers": {
"@type": "Offer",
"url": "https://www.example.com/event_offer/12345_201803180430",
"price": "30",
"priceCurrency": "USD",
"availability": "http://schema.org/InStock",
"validFrom": "2017-01-20T16:20-08:00"
},
"performer": {
"@type": "PerformingGroup",
"name": "Andy Lagunoff"
}
}
</script>I tag script definiscono l’elemento dalla riga 01 a quella 39 come script del tipo “application/ld+json“. Le informazioni successive si orientano così a programmi che sono in grado di scansionare i Linked Data nel formato JSON.
Sul primo livello si trovano le parole chiave “@context“ e “@type“ con i valori “http://schema.org” e “Event” (Righe 03 e 04). Un programma di parsing riceve l’istruzione che le seguenti informazioni sono da attribuire allo schema “Event” in base a schema.org; si tratta così di specifiche proprietà dell’evento descritto, rappresentate sotto forma di coppie nome-valore.
Sempre sul primo livello si trovano le proprietà “name“, “startDate“, “location“, “image“, “description“, “enddate“, “offers“ e “performer“ alle quali sono assegnate come valori le rispettive informazioni dell’evento. Un crawler può così identificare senza alcun dubbio l’informazione “Jan Lieberman Concert Series: Journey in Jazz“ come titolo dell’evento (name) e “2017-04-24T19:30-08:00“ come punto di inizio esatto (StartDate).
Analogamente a RDFa e microdati anche la sintassi JSON-LD supporta gli annidamenti (nesting). Così non viene assegnato alcun valore a una proprietà, bensì un (sotto)schema che può essere di nuovo specificato meglio con proprietà specifiche. Un caso di questo tipo si trova sul secondo livello del codice di esempio nelle righe 08, 27 e 35.
Ad esempio nella riga 08 viene definita la proprietà Event “location” come (sotto)schema del tipo “Place” e dotato delle proprietà “name” e “address”. La proprietà “address” viene definita di nuovo nella riga 11 come (sotto)schema del tipo “PostalAddress” e segnalato a sua volta con le proprietà, specifiche dello schema, “streetAddress“, “addressLocality“, “postalCode“, “addressRegion“ e “addressCountry“.
Ogni livello annidato viene racchiuso tra parentesi graffe e delimitato così dal livello sovraordinato.
Parte di codice (righe da 07 fino a 18)
"location": {
"@type": "Place",
"name": "Santa Clara City Library, Central Park Library",
"address": {
"@type": "PostalAddress",
"streetAddress": "2635 Homestead Rd",
"addressLocality": "Santa Clara",
"postalCode": "95051",
"addressRegion": "CA",
"addressCountry": "US"
}
},Schema.org mette così a disposizione dei gestori dei siti i tipi di dati sotto forma di una struttura ad albero gerarchica, che diventa sempre più specifica a partire dal tipo di dati più generale “Thing” (cosa).
Nel paragrafo seguente vi indichiamo come potete adattare l’esempio di Google al tipo di dati “Event” con le informazioni dell’evento presentate sopra.
Quarto passaggio: adattare il markup JSON-LD
La documentazione di Google comprende solo esempi che mostrano come i tipi di dati presentati si possano segnalare tramite JSON-LD. Se vengono utilizzati come modelli per un proprio markup di metadati, il codice deve essere in ogni caso adattato individualmente. In alcune circostanze è utile ricorrere alla documentazione di schema.org per il rispettivo tipo di dati, per saperne di più sull’uso di un preciso schema e delle possibili proprietà. Il seguente esempio indica una personalizzazione del codice di esempio di Google per il tipo di dati Event:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Event",
"name": " La grande maga Circe – una serata magica",
"startDate": "2017-11-20T20:00",
"url": " http://www.example.org/magacirce/2017-11-20-2000",
"location": {
"@type": "Place",
"sameAs": "http://www.example.org",
"name": "Montagna Incantata",
"address": {
"@type": "PostalAddress",
"streetAddress": " Via della Montagna Incantata 1",
"addressLocality": " Città magica",
"postalCode": "27890",
"addressCountry": "Paese magico"
}
},
"image": [
"https://example.com/photos/1x1/magacirce.jpg",
"https://example.com/photos/4x3/magacirce.jpg",
"https://example.com/photos/16x9/magacirce.jpg"
],
"description": "Ancora una volta torna la maga Circe per regalarvi una serata magica. Al suo fianco i suoi celebri assistenti: Polifemo e Ulisse.",
"endDate": "2017-11-20T23:00",
"doorTime": "2017-11-20T20:30",
"offers": {
"@type": "Offer",
"url": "http://www.example.org/events/magacirce/2017-11-20-2000/tickets ",
"price": "100",
"priceCurrency": "EUR",
"availability": "http://schema.org/InStock",
"validFrom": "2017-11-01T20:00"
},
"performer": {
"@type": "Person",
"name": "La grande maga Circe"
}
}
</script>Nel primo passaggio abbiamo sostituito tutti i valori del markup di esempio con i valori corrispondenti delle informazioni dell’evento presentate sopra. Così sono stati sostituiti i (sotto)schemi non appropriati e le relative proprietà. Ad esempio abbiamo tralasciato la proprietà “addressRegion“, visto che questa indicazione non è così comune. Al posto di “PerformingGroup” alla voce “performer” utilizziamo il (sotto)schema “Person”, visto che non abbiamo a che fare con una band, ma con una persona singola. Infine abbiamo aggiunto le informazioni al markup che non erano state incluse nel modello di Google. Così si trovano nelle righe 07 e 10, ad esempio, gli URL all’evento o al luogo dello stesso. Se necessario, desumete delle possibili proprietà dalla documentazione di schema.org.
Anche se create il markup con JSON-LD da zero, senza ricorrere ad alcun modello, dovreste controllare il corrispettivo tipo di dati sulla pagina di documentazione di Google. Qui il leader dei motori di ricerca indica per tutti i tipi di dati supportati sia le proprietà necessarie che quelle consigliate.
Fate attenzione al fatto che il markup JSON-LD comprenda in ogni caso le proprietà necessarie. Solo così il vostro sito prende parte al ranking per i risultati di ricerca ampliati come le Rich Cards. Inoltre tentate di mettere a disposizione anche i valori per tutte le proprietà consigliate per aumentare le vostre chance di ranking.
Gli esempi presentati nella documentazione di Google comprendono sempre tutte le proprietà necessarie e consigliate.
Se al vostro markup mancano delle proprietà importanti, testatele con il tool di validazione messo a disposizione da Google.
Quinto passaggio: testare il markup con JSON-LD
Tramite l’annidamento di schemi, (sotto)schemi e proprietà sono possibili dei markup complessi con JSON-LD. Tuttavia la separazione del markup HTML e di quello semantico garantisce una leggibilità notevolmente migliore rispetto agli altri formati di dati comparabili, che si basano su un’annotazione del codice sorgente. Per evitare errori nella programmazione, Google mette a disposizione con lo strumento di test per i dati strutturati una possibilità gratuita di convalidare il codice JSON-LD per la strutturazione dei dati.
- Inserite il codice JSON-LD tramite copia e incolla nell’apposito campo


A scelta inserite il markup da soli o l’URL della pagina web di cui volete testare il markup dei metadati.
- Avviate la convalida con un click su “Esegui test“


Durante la convalida il tool analizza i dati strutturati del markup JSON-LD e ne verifica la completezza. Gli utenti visualizzano il risultato dei dati analizzati in una tabella di riepilogo, che comprende errori e avvisi, nel caso in cui il tool riscontri degli errori di sintassi o dei dati mancanti.
Lo script di test creato da noi non presenta errori e contiene tutte le proprietà necessarie. Se, ad esempio, eliminiamo la proprietà indispensabile “startDate”, otteniamo il risultato seguente:


Allo stesso modo si possono individuare errori di sintassi, come una virgola mancante alla fine di una coppia nome-valore.


- Create un’anteprima
Oltre alla funzione di test lo strumento di test di Google per i dati strutturati mette a disposizione una modalità anteprima che dà ai webmaster un’idea di come potrebbe apparire un risultato di ricerca ampliato sulla base del markup testato e convalidato.
Errore nell’implementazione del markup con JSON-LD
Se malgrado il markup con JSON-LD Google non riproduce per il vostro sito nessun risultato di ricerca ampliato, di solito è perché vi è sfuggito un errore nella strutturazione dei dati. Verificate di nuovo il vostro codice e fate attenzione alle seguenti fonti di errore:
- Errore di sintassi: la sintassi JSON-LD è semplice e chiara, ma come nel caso di qualsiasi altro markup anche qui si insinuano di tanto in tanto degli errori. Un possibile errore conosciuto è la differenza tra i doppi apici usati nei codici ("…") e le virgolette tipografiche (“…“). Mentre le prime vengono usate nella programmazione, le seconde servono per segnalare un discorso diretto allo scritto. Visto che i programmi di elaborazione dei testi spesso convertono automaticamente i doppi apici nelle virgolette, per creare il vostro markup con JSON-LD utilizzate un editor come Notepad. Anche le virgolette singole, usate volentieri nei codici dei programmi, non sono consentite su JSON.
- Vocabolario non completo, sbagliato o non specificato: nella struttura ad albero gerarchica di schema.org è stabilito esattamente quali proprietà possano essere utilizzate con quale tipo di dati. Se utilizzate una proprietà non supportata da un tipo di dati, il corrispondente valore di Google non può essere interpretato. Il codice viene classificato come errato e lo strumento di test di Google per i dati strutturati riconosce errori simili.


Tutti i types e le properties del vocabolario di schema.org sono case-sensitive: fa quindi differenza se le lettere sono scritte maiuscole o minuscole.
Utilizzate sempre le pagine di documentazione di schema.org e convalidate il vostro codice JSON-LD grazie allo strumento di test per i dati strutturati. Inoltre prestate attenzione alle linee guida generali dei dati strutturati, oltre alle linee guide generali di Google Webmasters per evitare di infrangere le regole, cosa che potrebbe portare all’esclusione dal ranking dei risultati di ricerca ampliati.